Python入门课程NO67课 文件的读写高级操作
文件的读写缓冲区:
文件的读写缓冲区对应的是内存中的一块缓冲区:在对文件执行写操作时,会先将数据写到这个缓冲区,缓冲区写满以后再刷新到磁盘。在对文件执行读操作时,会先将文件的一部分数据预读到这块内存缓冲区,然后再从这块缓冲区里进行读取。在内存中进行读写远快于直接在磁盘中进行读写,所以在写入的时候,先写到内存缓冲区,当数据量大于内存缓冲区的容量时,再一次性刷新到磁盘。读取也是一样的道理,先将磁盘文件中的一批数据预读到内存里来,后续读取的时候直接在内存缓冲区里进行读操作,大大提高了读取的性能。
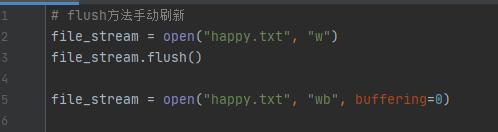
可以通过执行文件流对象flush方法手动地刷新内存缓冲区。
另外open方法中有一个buffering参数,当给buffering参数传递0时,会关闭这个内存缓冲区,该操作只适用于二进制模式。传递1时设置行缓冲模式,只能用于文本模式。所谓的行缓冲是指一行缓冲的大小,这里的一行以行尾的换行符来进行标识。传递的值大于1时表示设置固定的缓冲区大小。
文件的指针与定位:
file_stream.seek(offset, [from]):offset表示是偏移量,from表示从什么位置处开始进行定位,from的值为0时表示从文件头开始定位,为1时表示从当前位置开始定位,为2时表示从文件尾开始定位。from的值默认为0。如需从当前位置进行定位,必须以二进制模式来打开文件。

可以把文件指针形象地理解为箭头,一开始这个箭头指向文件的首行,应用程序读取文件时,从箭头指向的位置处开始读取。每读完一行,箭头就下移一行。
指定文件编码:
在执行open函数获取文件流对象时,可以通过encoding参数来指定文件读写时的编码。只有当文件自身编码和代码书写编码保持一致时,才能正确的读取文件内容,否则将抛出异常。例如我们用编辑器打开hello.txt输入极客小将四个字,之后保存为uft-8编码格式。

如果我们改成以ascii编码方式读取,那么就会抛出错误异常。

值得一提的是可以utf-8编码读取ascii编码的文件,因为utf-8字符集涵盖了ascii字符集,所以使用utf-8编码来读取文件时,能正确的编解码,而不会抛出异常信息。
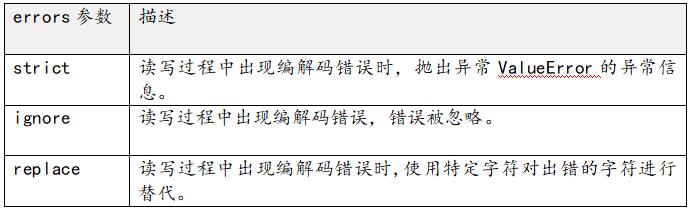
对文件读写进行错误处理:open方法中的errors参数,用来控制出现编码和解码的错误时该如何处理。errors参数只能用于文本模式。
举例说明:


- 上一篇
Python入门课程NO66课 文件的读写操作
在Python中可以通过内置的open函数来对文件进行读写操作。open(file, mode, buffering, encoding,errors)。file 对应的是文件的路径名,mode 对应的是文件的打开模式,buffering对应的是文件缓冲,encoding对应的是文件数据流的编码, errors表示的是对文件的读写过程中出现了
- 下一篇
Python入门课程NO68课 StringIO与BytesIO
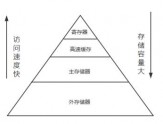
我们通过open方法来打开硬盘上的文件,并获得一个文件流对象,然后通过文件流对象对文件进行读写操作。计算机中的存储设备按其访问速度和容量大小,被组织成了下图所示的金字塔形状的层次结构:我们读写的硬盘文件,存储在外存储器中,从图可看出在硬盘中进行数据读写,远慢于
