资讯内容
爬虫如何抓取网页数据
 AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台
AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台
爬虫抓取网页数据的方法:AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台
将网址当参数传递给requests包的get方法就可以爬到简单网页上面的所有信息,然后用“print”语句打印出来就可以了AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台
示例如下:AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台
爬取百度首页的网页内容:AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台
代码如下:
AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台
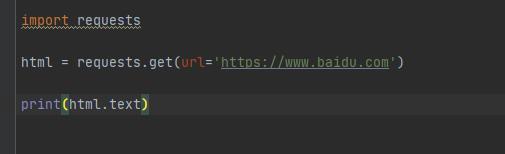 AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台
AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台
执行结果如下:AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台
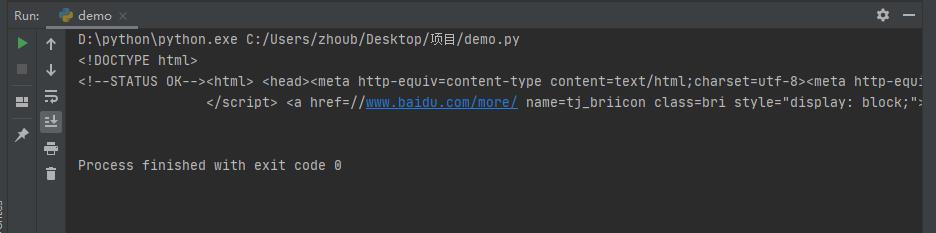 AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台
AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台
更多python知识,请关注:Python自学网!!AwF少儿编程网-Scratch_Python_教程_免费儿童编程学习平台

- 上一篇

python如何保留2位小数
简介python保留2位小数的方法:首先打开编辑器pycharm,新建变量a;然后利用round函数将a的值保留2位数,并打印结果;接着在窗口中选择run;最后最后运行这个程序即可。本教程操作环境:windows7系统、pycharm2020版,DELLG3电脑,该方法适用于所有
- 下一篇

看看 Python Django开发 异常及解决办法
简介相关免费学习推荐:python视频教程1.Djangoxadmin数据迁移报错ImportError:cannotimportname‘QUERY_TERMS’在进行Djangoxadmin数据迁移时报错:fromdjango.db.models.sql.queryimportLOOKUP_SEP,
相关资讯
